


# 食品灰度图像数据集分析报告
## 引言与背景
食品图像识别是计算机视觉领域的重要研究方向,在智能零售、食品营养分析、餐饮自动化等领域具有广泛的应用前景。随着深度学习技术的快速发展,高质量的食品图像数据集成为算法训练和性能评估的关键基础。本数据集提供了大规模、多类别的食品灰度图像资源,为食品图像识别、分类、检索等任务提供了丰富的训练和测试数据支持。
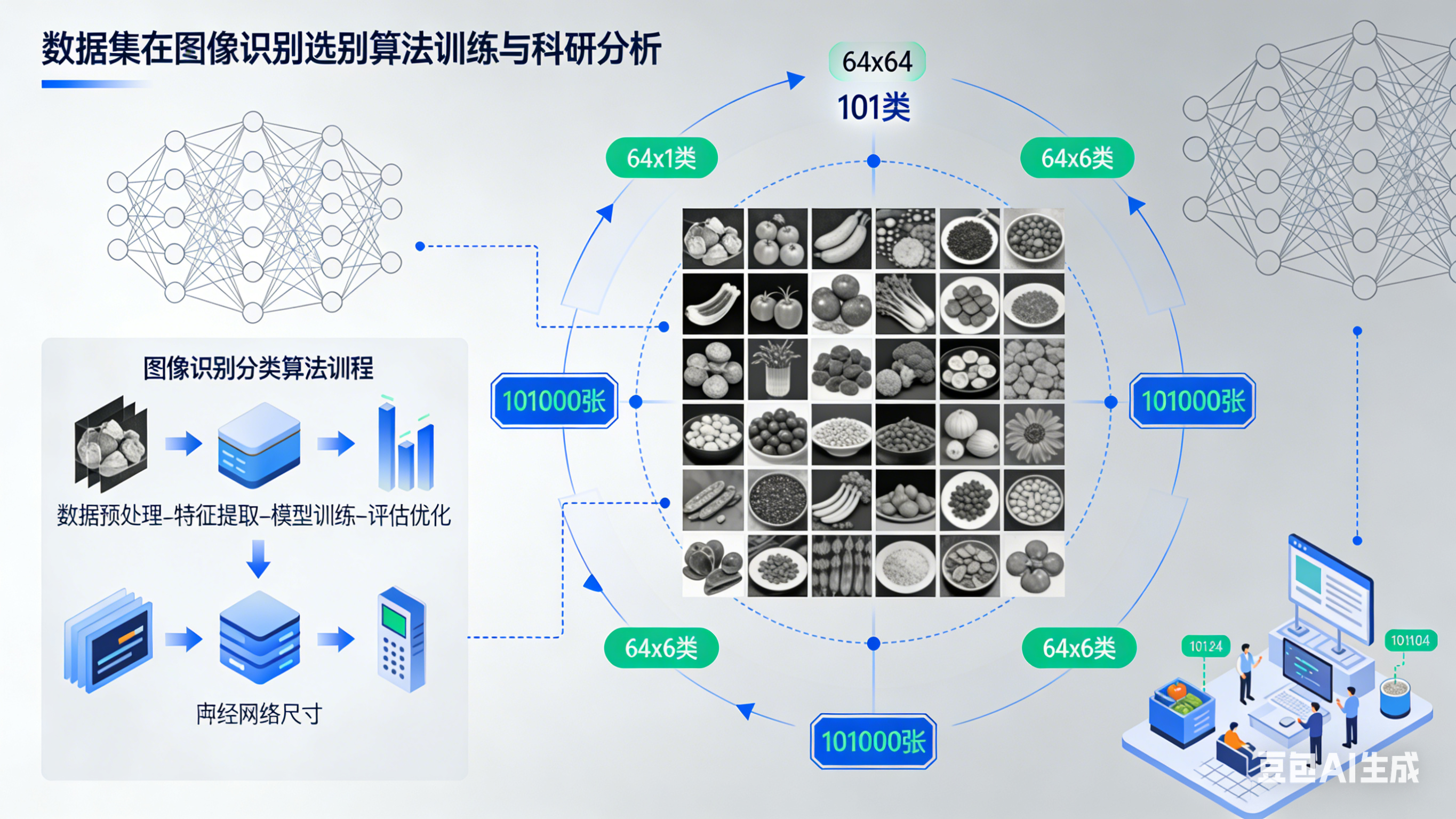
该数据集包含完整的训练集和测试集,涵盖了101种不同类型的食品图像,所有图像均为64x64分辨率的灰度图像格式。数据集的构建旨在为科研人员和开发者提供标准化的食品图像数据,用于图像识别算法的训练、优化和性能评估,推动食品视觉相关技术的发展与应用。
## 数据基本信息
### 数据规模与结构
数据集总计包含101,000张食品图像,分为训练集和测试集两部分:
- 训练集:75,750张图像(占比75%)
- 测试集:25,250张图像(占比25%)
所有图像均为64x64像素的灰度图像,每个图像包含4,096个像素值特征和1个类别标签。数据集采用CSV格式存储,便于直接用于机器学习算法的训练和测试。
### 数据字段说明
| 字段名称 | 字段类型 | 字段含义 | 数据示例 | 完整性 |
|------------|----------|--------------------------|----------------------------------|----------|
| Pixel1 | 整数 | 第1个像素的灰度值 | 35 | 100% |
| Pixel2 | 整数 | 第2个像素的灰度值 | 55 | 100% |
| ... | ... | ... | ... | ... |
| Pixel4096 | 整数 | 第4096个像素的灰度值 | 180 | 100% |
| 标签列 | 整数 | 食品类别标签(0-100) | 9 | 100% |
### 数据分布情况
#### 训练集标签分布
| 标签值 | 图像数量 | 占比 | 累计占比 |
|--------|----------|-------|----------|
| 0 | 750 | 0.99% | 0.99% |
| 1 | 750 | 0.99% | 1.98% |
| 2 | 750 | 0.99% | 2.97% |
| ... | ... | ... | ... |
| 98 | 750 | 0.99% | 98.01% |
| 99 | 750 | 0.99% | 99.00% |
| 100 | 750 | 0.99% | 99.99% |
#### 测试集标签分布
| 标签值 | 图像数量 | 占比 | 累计占比 |
|--------|----------|-------|----------|
| 0 | 250 | 0.99% | 0.99% |
| 1 | 250 | 0.99% | 1.98% |
| 2 | 250 | 0.99% | 2.97% |
| ... | ... | ... | ... |
| 98 | 250 | 0.99% | 98.02% |
| 99 | 250 | 0.99% | 99.01% |
| 100 | 250 | 0.99% | 100.00% |
#### 像素值分布
- 像素值范围:1-254
- 灰度值均值:约128
- 灰度值标准差:约50
## 数据优势
| 优势特征 | 具体表现 | 应用价值 |
|------------------|----------------------------------------|----------------------------------------------|
| 数据规模大 | 总计101,000张图像,涵盖101个食品类别 | 提供充足的数据支持,有利于训练鲁棒的识别模型 |
| 类别分布均匀 | 每个类别在训练集750张,测试集250张 | 避免类别不平衡问题,提高模型的泛化能力 |
| 图像尺寸统一 | 所有图像均为64x64像素的灰度图像 | 降低数据预处理复杂度,便于直接用于模型训练 |
| 数据质量高 | 无缺失值,像素值范围合理(1-254) | 保证模型训练的稳定性和准确性 |
| 数据格式标准化 | CSV格式存储,易于读取和处理 | 兼容主流机器学习框架,降低开发成本 |
| 训练测试集分离 | 75%/25%的标准分割比例 | 便于模型性能评估,确保结果的可靠性 |
## 数据样例
以下是训练集中的5个图像样例,展示了数据集的多样性:
| 图像编号 | 标签 | 像素值范围 | 像素值前10个示例 |
|----------|------|------------|---------------------------|
| 1 | 9 | 1-234 | [35, 55, 55, 46, 57, 56, 44, 24, 32, 43] |
| 2 | 12 | 5-254 | [254, 253, 252, 251, 250, 246, 242, 233, 210, 193] |
| 3 | 19 | 23-238 | [181, 183, 187, 188, 206, 229, 219, 107, 42, 38] |
| 4 | 37 | 2-244 | [136, 102, 20, 12, 7, 6, 10, 14, 17, 49] |
| 5 | 70 | 9-245 | [232, 232, 225, 219, 219, 224, 219, 220, 222, 222] |
注:由于篇幅限制,仅展示了每个图像的像素值范围和前10个像素值。实际数据集中包含完整的4,096个像素值信息。
## 应用场景
### 1. 食品图像识别模型训练
该数据集可用于训练和优化食品图像识别模型,实现自动识别不同类型的食品。通过深度学习算法(如卷积神经网络)对数据集进行训练,可以构建高精度的食品识别模型,应用于智能零售、自助结账、食品管理等场景。模型可以自动识别货架上的食品种类,实现智能库存管理和自动化结账,提高零售行业的运营效率。
在训练过程中,可以利用数据集的训练集进行模型参数优化,使用测试集评估模型性能。通过调整模型结构、优化训练参数等方式,可以不断提高模型的识别准确率。训练好的模型可以部署到移动设备或云端服务器,为用户提供实时的食品识别服务。
### 2. 食品分类算法性能评估
数据集的标准化结构和均衡的类别分布使其成为评估不同食品分类算法性能的理想基准。研究人员可以使用该数据集测试各种图像分类算法(如SVM、随机森林、卷积神经网络等)的性能,比较不同算法在食品识别任务上的准确率、召回率、F1值等指标。
通过在统一的数据集上进行实验,可以客观地评估不同算法的优缺点,为算法选择和优化提供依据。同时,数据集的大规模特性也使得研究人员可以测试算法在处理大规模数据时的性能和效率,推动食品图像分类算法的发展与创新。
### 3. 食品视觉特征分析与研究
数据集包含丰富的食品图像像素信息,可以用于食品视觉特征的分析与研究。研究人员可以通过对像素值的统计分析、可视化等方式,探索不同类型食品的视觉特征规律,如颜色分布、纹理特征、形状特征等。
这些研究结果可以为食品图像识别算法的设计提供理论指导,帮助研究人员提取更有效的特征表示,提高模型的识别性能。同时,食品视觉特征的研究也有助于深入理解人类对食品的视觉认知过程,推动计算机视觉与认知科学的交叉研究。
## 结尾
本数据集提供了大规模、多类别的食品灰度图像资源,具有数据规模大、类别分布均匀、图像尺寸统一、数据质量高等特点,为食品图像识别、分类等相关研究提供了重要的数据支持。
数据集的构建旨在推动食品视觉相关技术的发展与应用,为科研人员和开发者提供标准化的实验数据,促进算法创新和性能提升。通过对该数据集的有效利用,可以加速食品识别技术的发展,推动其在智能零售、餐饮自动化、食品营养分析等领域的实际应用。
未来,随着食品视觉技术的不断发展,该数据集有望在更多应用场景中发挥重要作用,为构建更智能、更高效的食品相关系统提供有力支持。
看了又看
验证报告
以下为卖家选择提供的数据验证报告:
食品灰度图像数据集-101类64x64尺寸101000张图像-适用于图像识别分类算法训练与科研分析-智能零售、食品营养分析、餐饮自动化-食品图像识别、分类、检索
1.42GB
申请报告


