



基于自动化抽取算法的中文概念知识图谱数据集
作者:浙江大学
数据集介绍
OpenConcepts (http://openconcepts.openkg.cn/) 是一个基于自动化知识抽取算法的大规模中文概念图谱。概念是人脑对事物的本质反应,能够帮助机器更好的理解自然语言。相较于传统的知识图谱,OpenConcepts包含大量中文细粒度概念,且具备自动更新、自动扩充的能力。比如对于“刘德华”这一实体,OpenConcepts不仅包含“香港歌手”、“演员”等传统概念,还具有“华语歌坛不老男歌手”、“娱乐圈绝世好男人”等细粒度标签。
数据预览
【数据构建】
构建知识图谱具有诸多挑战。早年的英文知识图谱如CyC、WordNet以及中文知识库如HowNet等大多通过专家手工构建,其构建成本非常高昂。OpenConcepts采取自动化构建的方式,基于海量的中文网页数据和若干开放的中文知识库,通过自动化信息抽取、短语挖掘等自然语言处理技术,实现概念知识图谱的自动化构建。
相较于传统的概念知识图谱,OpenConcepts的特点在于:
(1)OpenConcepts包含大量的中文细粒度概念,这部分细粒度概念填补了中文细粒度知识的空白。
(2)OpenConcepts是基于机器学习的自动抽取方式,其整合了诸多自然语言处理算法并形成一套完整的知识抽取框架,具备自动化抽取、自动化扩展、自动化更新的能力。
OpenConcepts的自动化构建主要分为两大模块:
(1)概念知识的自动化抽取。
(2)概念知识的融合。
我们首先通过开放的知识库、百科InfoBox等结构化、半结构化数据抽取粗粒度的概念。对于细粒度的概念,我们采取短语挖掘和序列标注相结合的策略,通过实体-概念模板和无监督短语挖掘构造弱监督样本,并基于迭代的降噪学习训练基于序列标注的概念抽取模型(http://openconcepts.openkg.cn/concept_extract/ ),在离线测试集上概念抽取模型准确率可达0.89,召回率可达0.85。然后,我们对抽取到的不同的实体和概念进行融合,并通过贝叶斯估计过滤掉低置信度的概念。
此外,我们也构造人工规则约束对高层次的概念进行人工干预,保证准确率。
【数据预览】
中文概念知识图谱数据集OpenConcepts数据情况如下图所示(部分类型数据并未开放):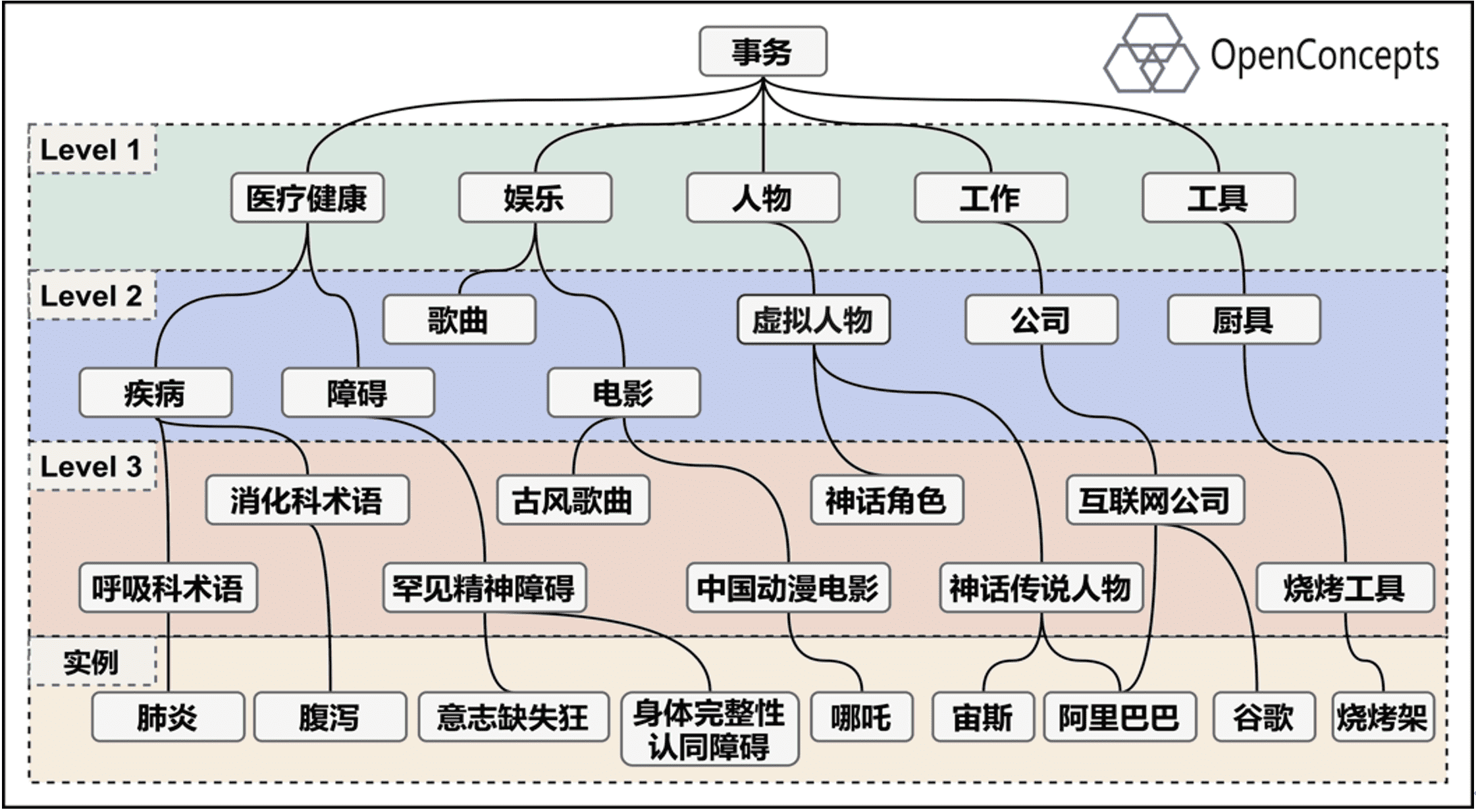
OpenConcepts包含五个文件:
level1_level2.sample.txt: level1 和level2对应的概念知识
concept_sample.txt:部分概念的样例数据
dataset_part1.txt:第一部分数据文件
dataset_part2.txt:第二部分数据文件
concept_query_tagging.txt:和用户Query相关的概念弱标注数据
seed_concept_patterns.txt: 种子模板数据
【数据规模和用途】
本次,我们开源了OpenConcepts中的440万概念核心实体,以及5万概念和1300万实体-概念三元组。这些数据包括了常见的人物、地点等通用实体。我们的数据还在不断更新中。本次开源的数据也可在openkg.cn 获取,OpenConcepts能够为智能推荐、智能问答、人机对话等应用提供数据支持。
构建知识图谱具有诸多挑战。早年的英文知识图谱如CyC、WordNet以及中文知识库如HowNet等大多通过专家手工构建,其构建成本非常高昂。OpenConcepts采取自动化构建的方式,基于海量的中文网页数据和若干开放的中文知识库,通过自动化信息抽取、短语挖掘等自然语言处理技术,实现概念知识图谱的自动化构建。
相较于传统的概念知识图谱,OpenConcepts的特点在于:
(1)OpenConcepts包含大量的中文细粒度概念,这部分细粒度概念填补了中文细粒度知识的空白。
(2)OpenConcepts是基于机器学习的自动抽取方式,其整合了诸多自然语言处理算法并形成一套完整的知识抽取框架,具备自动化抽取、自动化扩展、自动化更新的能力。
OpenConcepts的自动化构建主要分为两大模块:
(1)概念知识的自动化抽取。
(2)概念知识的融合。
我们首先通过开放的知识库、百科InfoBox等结构化、半结构化数据抽取粗粒度的概念。对于细粒度的概念,我们采取短语挖掘和序列标注相结合的策略,通过实体-概念模板和无监督短语挖掘构造弱监督样本,并基于迭代的降噪学习训练基于序列标注的概念抽取模型(http://openconcepts.openkg.cn/concept_extract/ ),在离线测试集上概念抽取模型准确率可达0.89,召回率可达0.85。然后,我们对抽取到的不同的实体和概念进行融合,并通过贝叶斯估计过滤掉低置信度的概念。
此外,我们也构造人工规则约束对高层次的概念进行人工干预,保证准确率。
【数据预览】
中文概念知识图谱数据集OpenConcepts数据情况如下图所示(部分类型数据并未开放):
OpenConcepts包含五个文件:
level1_level2.sample.txt: level1 和level2对应的概念知识
concept_sample.txt:部分概念的样例数据
dataset_part1.txt:第一部分数据文件
dataset_part2.txt:第二部分数据文件
concept_query_tagging.txt:和用户Query相关的概念弱标注数据
seed_concept_patterns.txt: 种子模板数据
【数据规模和用途】
本次,我们开源了OpenConcepts中的440万概念核心实体,以及5万概念和1300万实体-概念三元组。这些数据包括了常见的人物、地点等通用实体。我们的数据还在不断更新中。本次开源的数据也可在openkg.cn 获取,OpenConcepts能够为智能推荐、智能问答、人机对话等应用提供数据支持。
看了又看
验证报告
以下为卖家选择提供的数据验证报告:

基于自动化抽取算法的中文概念知识图谱数据集
20.26MB
申请报告


